This Looks Like That... Does it? Shortcomings of Latent Space Prototype Interpretability in Deep Networks
Abstract
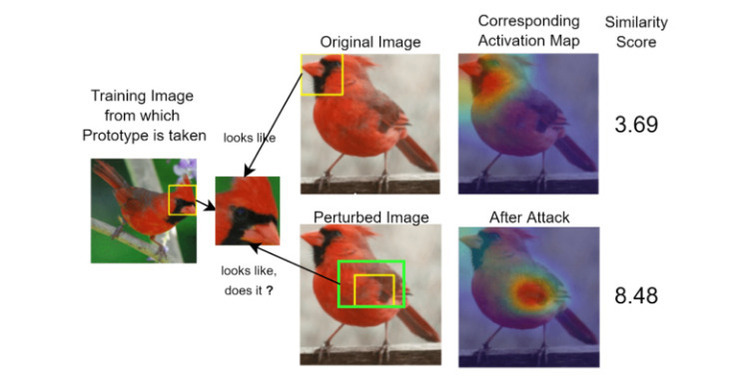
Deep neural networks that yield human interpretable decisions by architectural design have become an increasingly popular alternative to post hoc interpretation of traditional black-box models. Among these networks, the arguably most widespread approach is so-called prototype learning, where similarities to learned latent prototypes serve as the basis of classifying unseen data. In this work, we point to a crucial shortcoming of such approaches. Namely, there is a semantic gap between similarity in latent space and input space, which can corrupt interpretability. We design two experiments that exemplify this issue on the socalled ProtoPNet. We find that its interpretability mechanism can be led astray by crafted noise or JPEG compression artefacts, which can lead to incoherent decisions. We argue that practitioners ought to have this shortcoming in mind when deploying prototype-based models in practice.