Few-shot Steerable Alignment: Adapting Rewards and LLM Policies with Neural Processes
Abstract
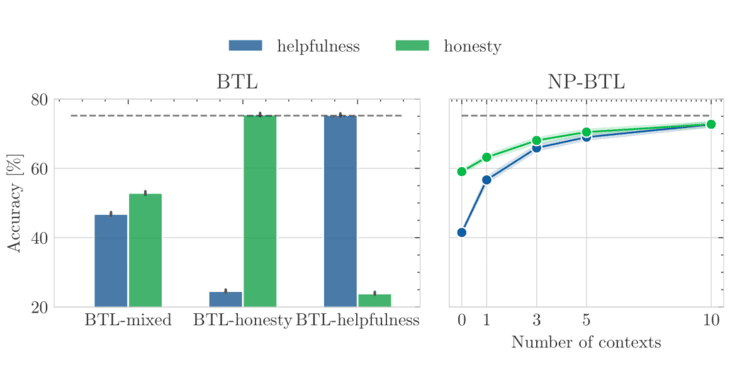
As large language models (LLMs) become increasingly embedded in everyday applications, ensuring alignment with diverse individual preferences is a key challenge. Most current methods assume homogeneous objectives and rely on single-objective fine-tuning, which can miss heterogeneous and partially unobservable user preferences. This paper proposes a framework for few-shot steerable alignment, where latent user preferences are inferred from a small sample of their choices. The method extends the Bradley-Terry-Luce model to heterogeneous preferences with unobserved variability and introduces a practical implementation for reward modelling and LLM fine-tuning via functional parameter-space conditioning. This enables adaptation to individual preferences at inference time and supports outputs across a continuum of behavioural modes. Experiments show data-efficient alignment with diverse human preferences.