Learning Reasoning Reward Models from Expert Demonstration via Inverse Reinforcement Learning
Abstract
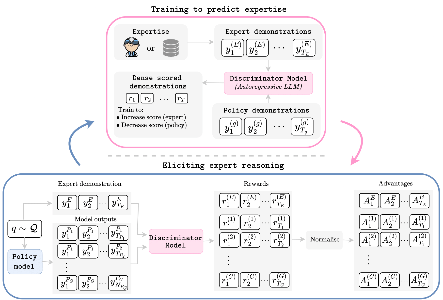
Reasoning in large language models is typically trained via supervised fine-tuning on expert traces or reinforcement learning with outcome-based rewards. Supervised imitation does not directly optimise sequential decision quality, while outcome-based RL requires explicit reward design. This paper proposes an inverse reinforcement learning framework that learns partially dense token-level reasoning rewards directly from expert demonstrations. The learned reward is used both as a dense training signal and as an inference-time reranking signal. Compared with supervised baselines, the approach reports gains on GSM8K (79% vs 56%) and MedReason (74% vs 65%), and up to 12 percentage-point improvements through reward-guided reranking on Llama3 architectures. The learned dense rewards also provide interpretable step-wise diagnostics for localising reasoning errors.